
【CDGC】インフォマティカのデータカタログでRedshift ServerlessとS3をスキャンしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
こんにちは、データ事業本部の渡部です。
今回はインフォマティカのデータカタログCloud Data Governance and Catalog(以降、CDGC)で、Redshift Serverless と S3 をスキャンしみました。
手順としては本当に簡単なのですが、詰まったポイントもあったのでブログにまとめようと思います。
インフォマティカのメタデータ収集、一言でまとめると お手軽スキャン です。
Redshift Serverlessのスキャン
Redshift Serverlessに作成したテーブルをスキャンしていきます。
他のメタデータ管理ツールでは、Redshiftがプロビジョンドクラスターのみのスキャン対応だったため、インフォマティカでRedshift Serverlessがスキャンできるか不安だったのですが、スキャン可能でした。
テーブル定義は以下のとおりです。
create table mart.t_event_category_ticket_revenue(
eventid integer not null ,
catid smallint not null ,
eventname varchar(200),
catname varchar(10),
total_qtysold integer,
total_pricepaid decimal(15,2),
updated_at timestamp
)
diststyle auto
sortkey auto;
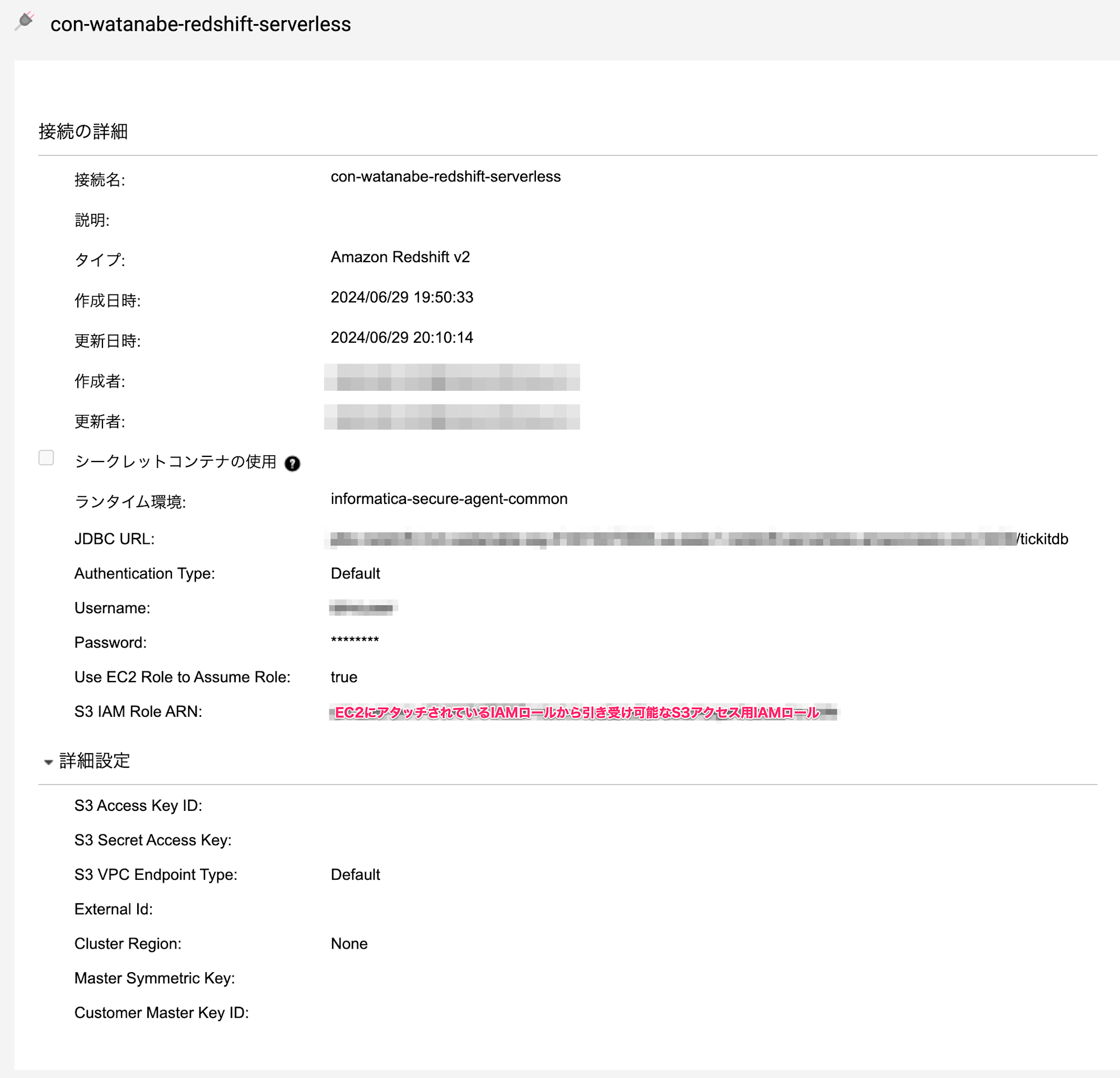
Redshiftのコネクタは以下のとおり作成しました。
RedshiftについてはDB認証、処理で必要なS3にアクセスするための権限についてはEC2のRoleからAssumeできるRoleを指定しました。
それではスキャンするための設定を始めます。
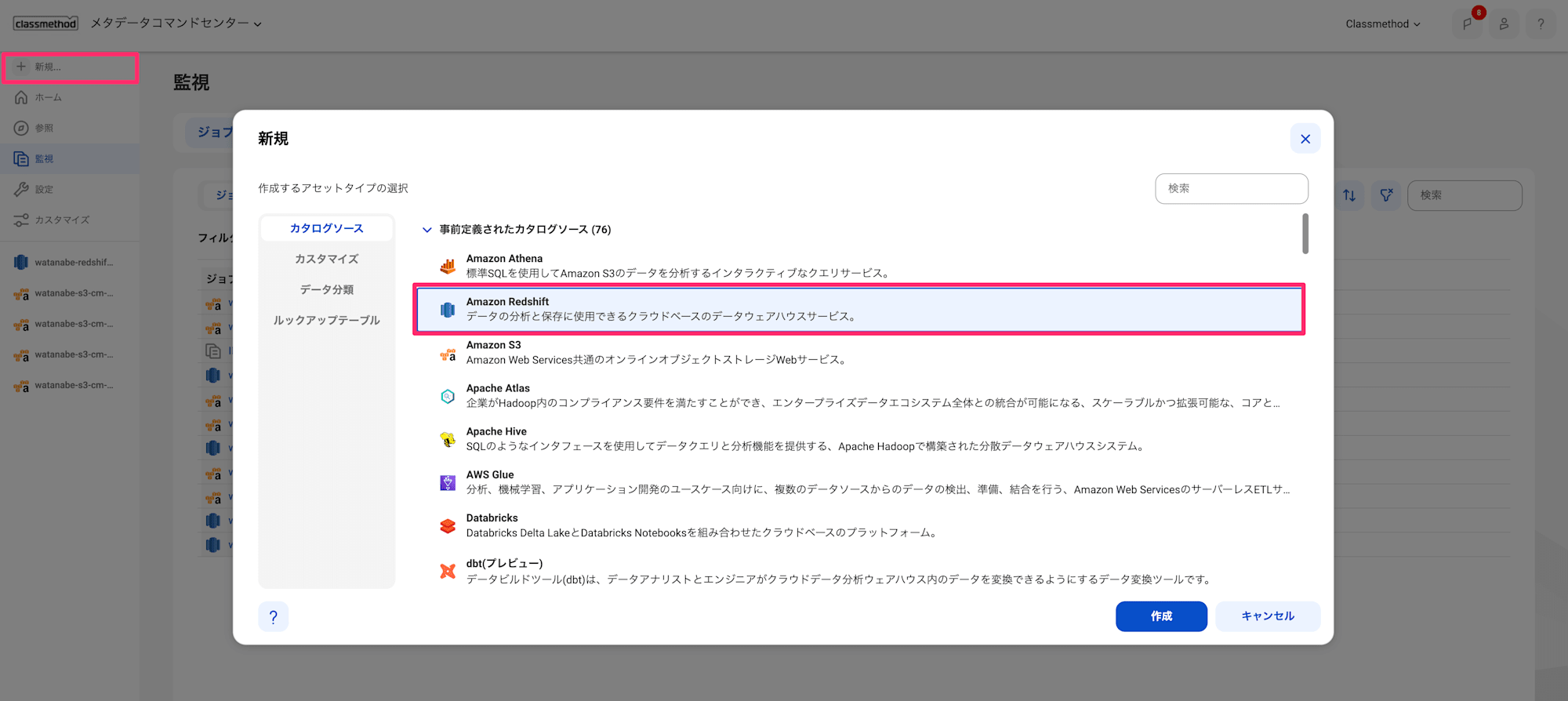
まずメタデータコマンドセンター(以降、MCC)でRedshiftカタログソースの作成をします。
新規 > Amazon Redshift を選択します。
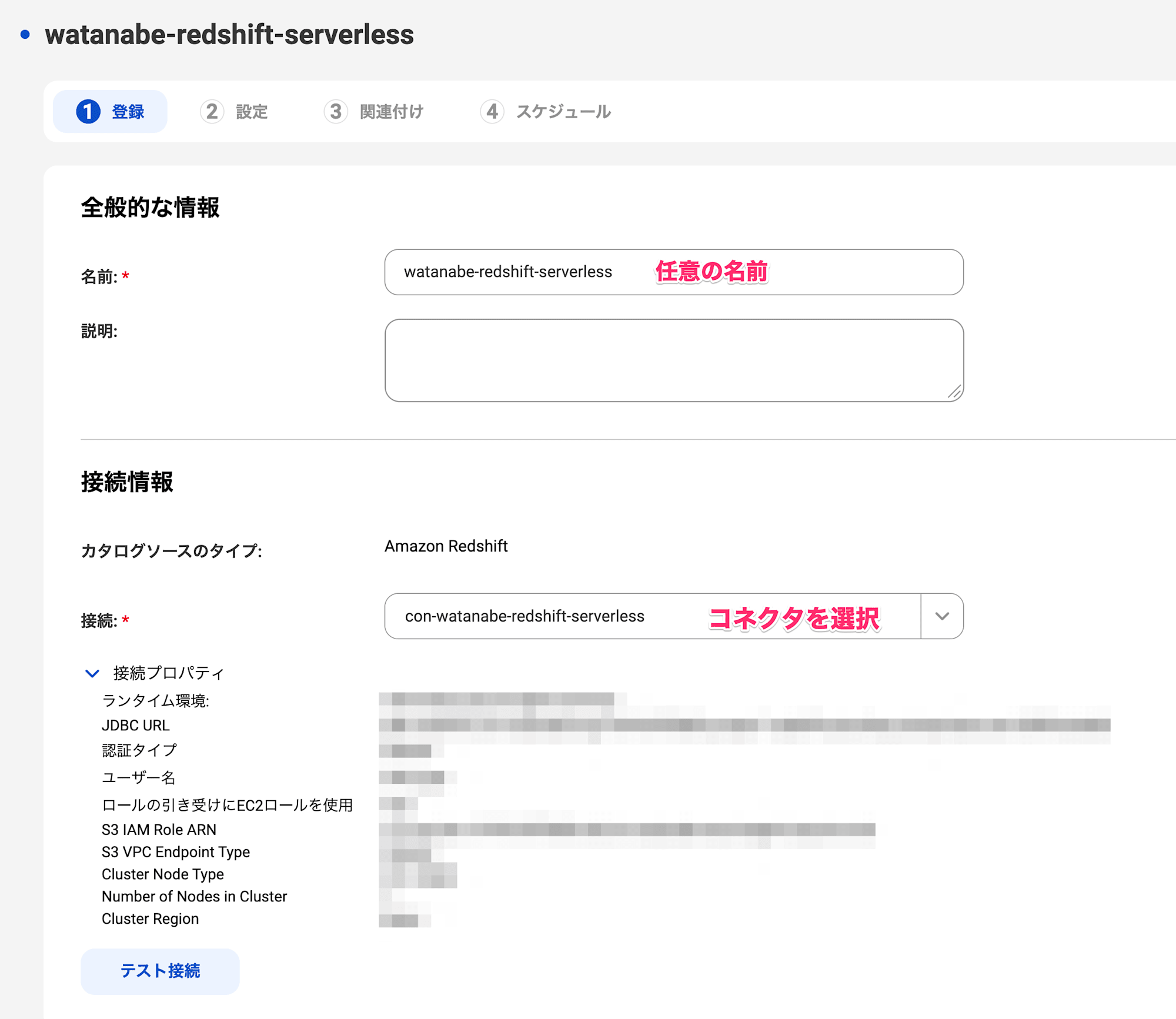
以下を設定します。テスト接続が成功すればOKです。
名前:任意のカタログソース名接続:Redshiftのコネクタ
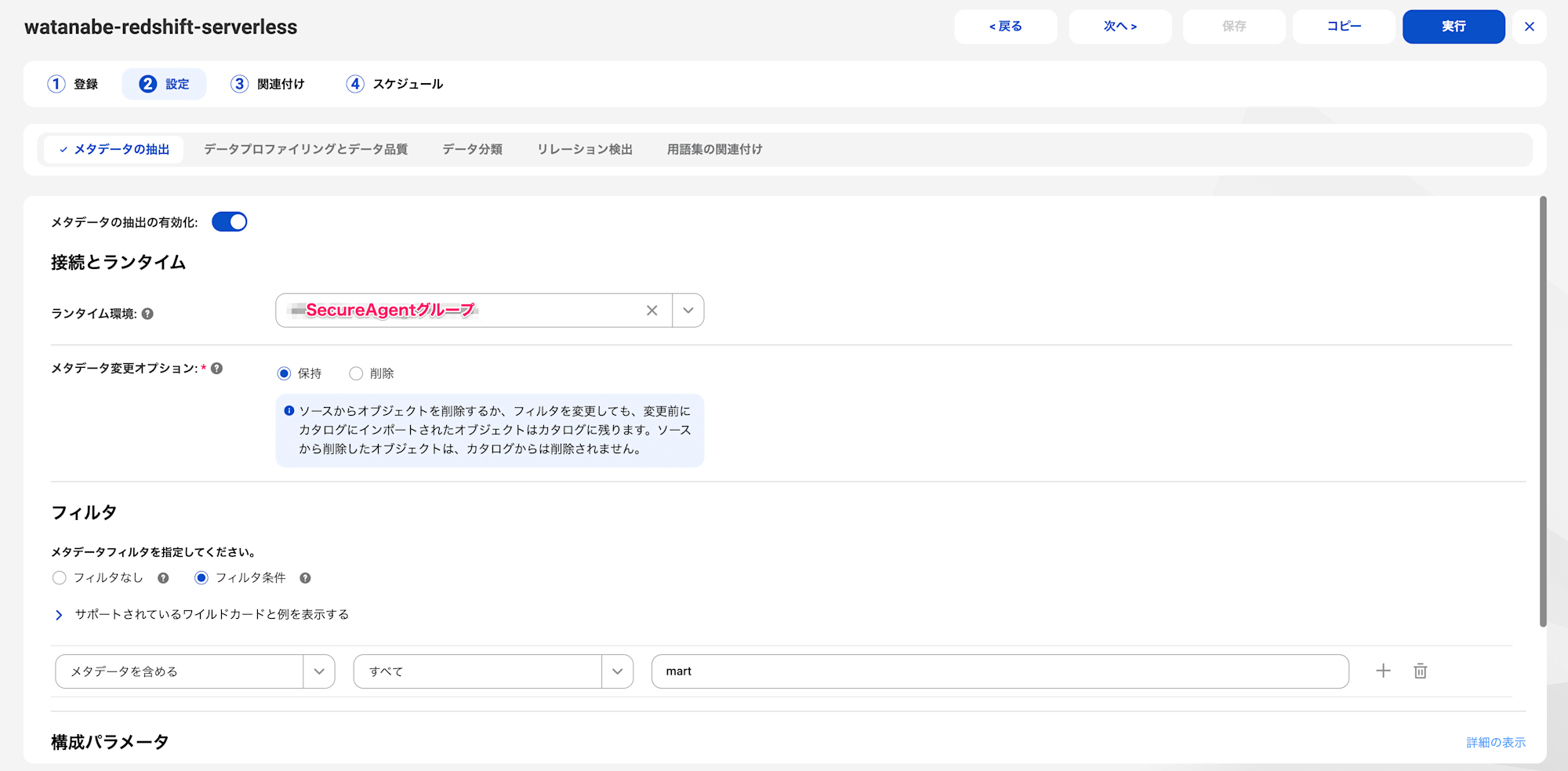
メタデータの抽出タブで以下のとおり設定します。
ランタイム環境:SecureAgentグループメタデータ変更オプション:保持(画像のとおりカタログソース変更時に、以前にインポートしたオブジェクトを残すか削除かを選択可能です)フィルタ:メタデータを含める、すべて、martを選択します。
「フィルタってどうやって書けばいいんだ・・・」と思ったのですが、トグルを開くと記載方法が詳しく記載されていました。ユーザーフレンドリーです。

他のタブは特にいじらず、デフォルトのまま保存をします。
早速スキャン実行をしてみました。
しかし・・・社内環境での初めてのスキャンは失敗に終わりました。
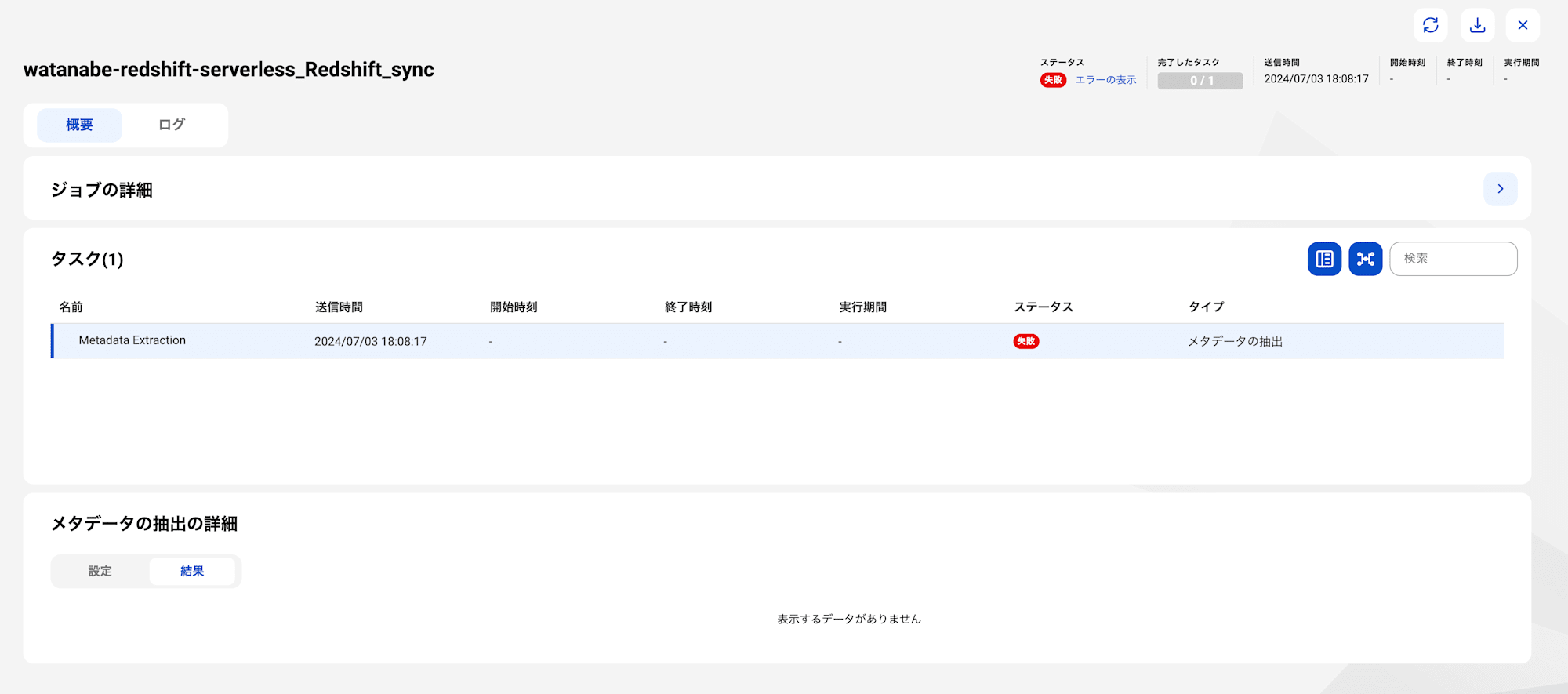
ログを確認してみます。
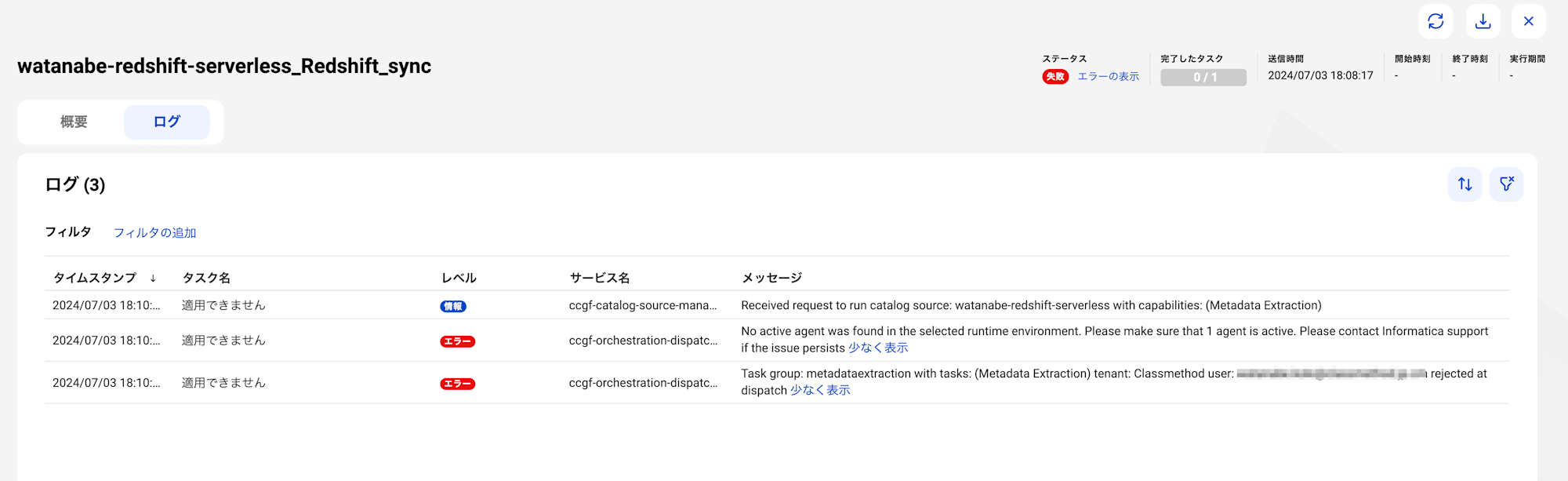
No active agent was found in the selected runtime environment.
アクティブなSecureAgentがないとのことです。
「あれ?EC2起動しているはずだけど」と思い、管理者画面でランタイムを確認してみました。
しかし、SecureAgentグループ内には実行中のSecureAgentが存在します。
SecureAgentグループ内で起動しているSecureAgent間でロードバランスする仕組みが存在するので問題ないはずです。

「もしかしてCDGCサービスが有効化されていないか?」と思いましたが、有効です。
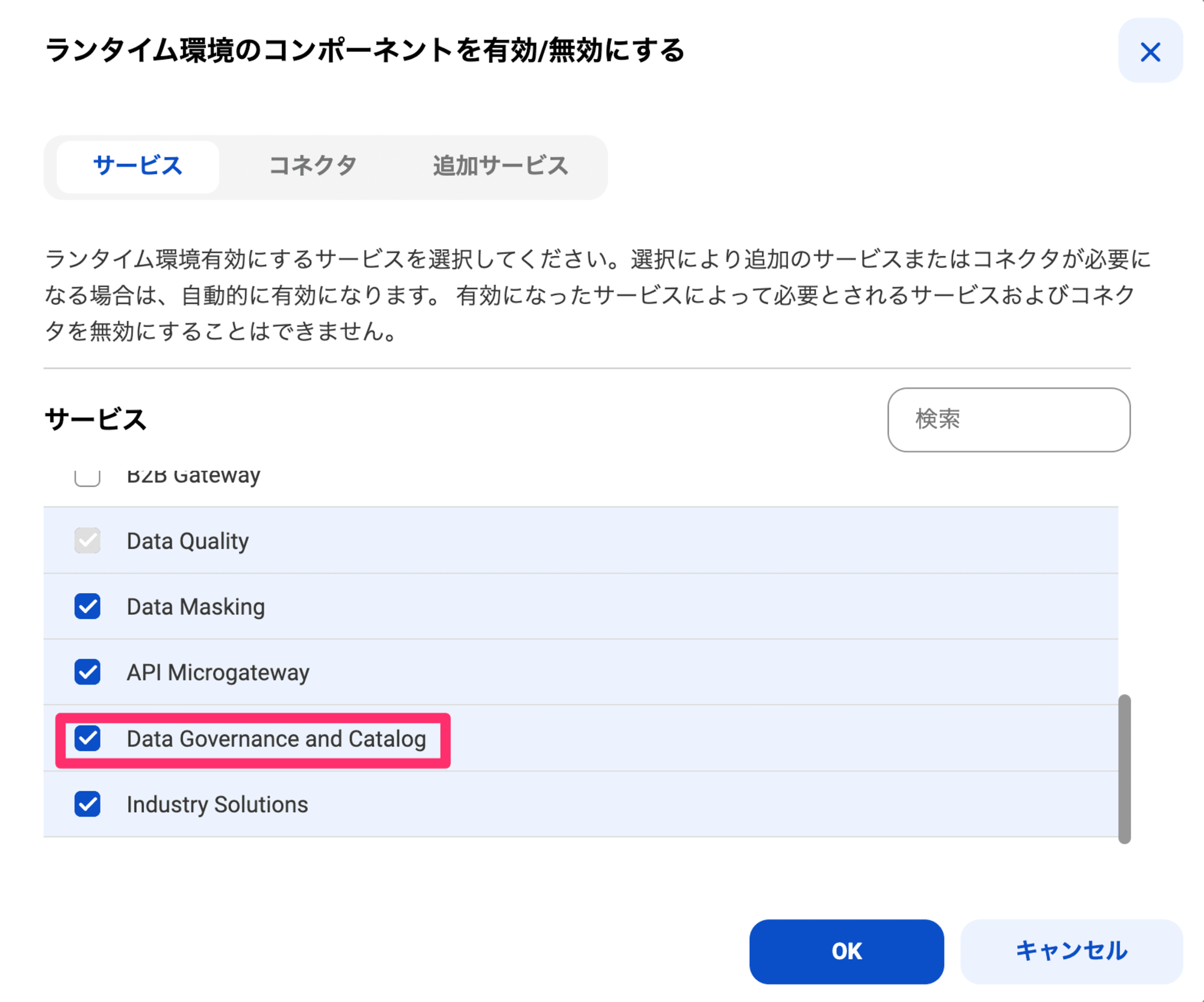
このあとインフォマティカのDocumentを確認してみたり、Knowledge Baseを漁ったりしてみましたが、同じような事象が見つかりません。
時間を費やして途方に暮れていたところ、SecureAgentグループに停止中のSecureAgentがあることが目に止まりました。
「まさかな〜」と思いつつ、SecureAgentグループから停止中のSecureAgentを削除して、スキャン再実行してみました。

・・・すると待ち望んだ緑色が。
メタデータ抽出が成功しました。
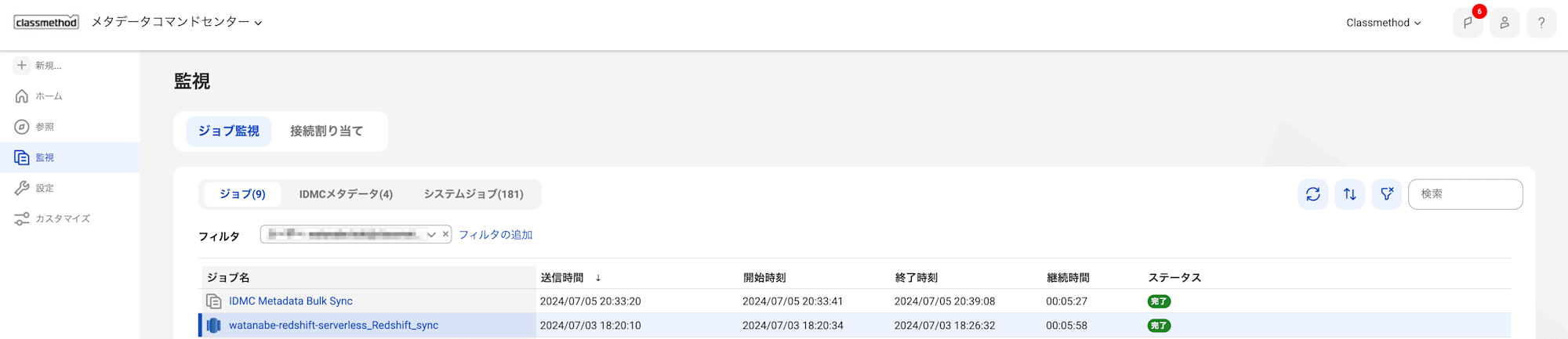
どうやらSecureAgentグループ内に停止しているSecureAgentがあると、MCCのメタデータ抽出ジョブは失敗してしまうようです。
ここはCDIのタスクなどとは違うところですね。勉強になりました。
ジョブの履歴を確認すると、冒頭に載せたテーブルがスキャンされていそうなことが確認できました。
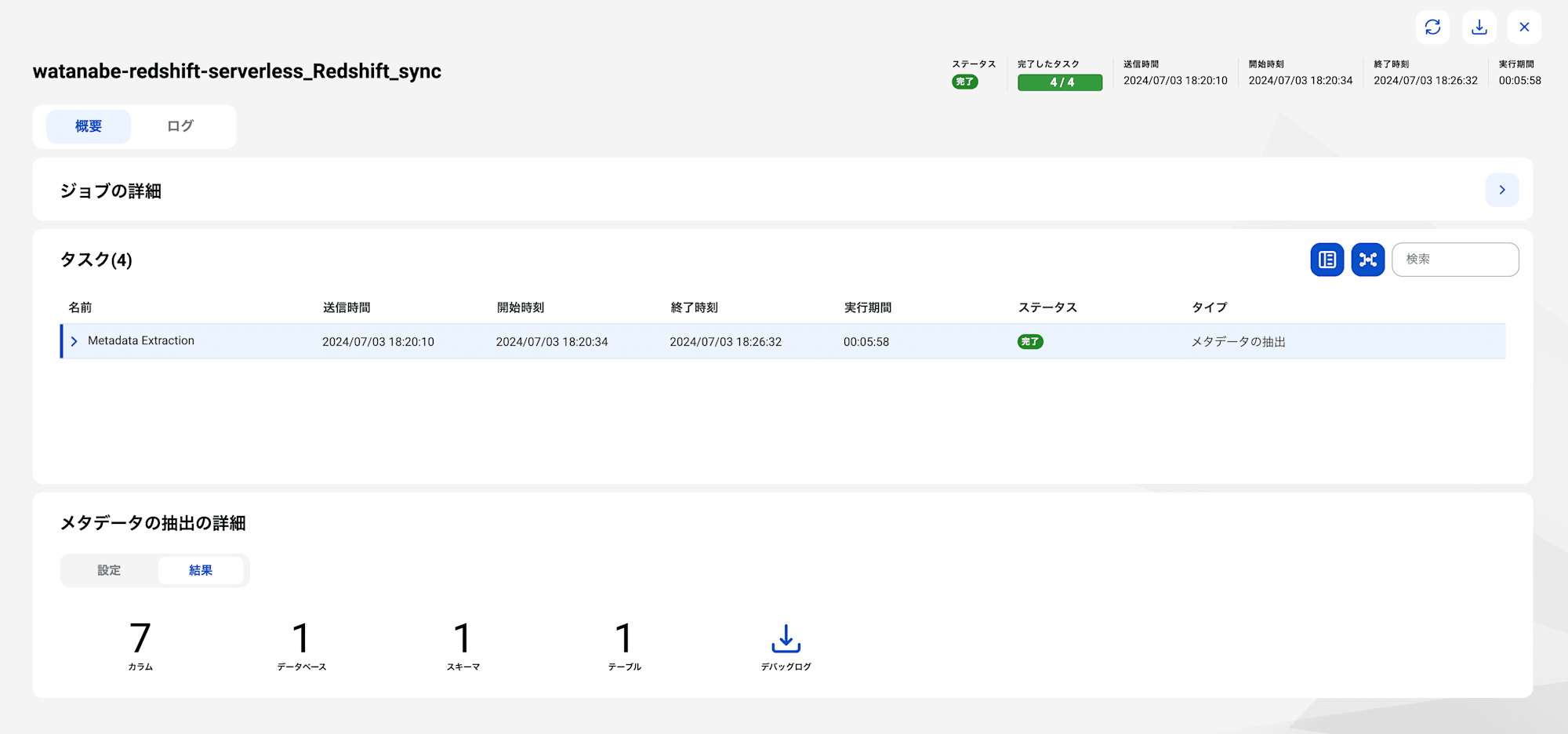
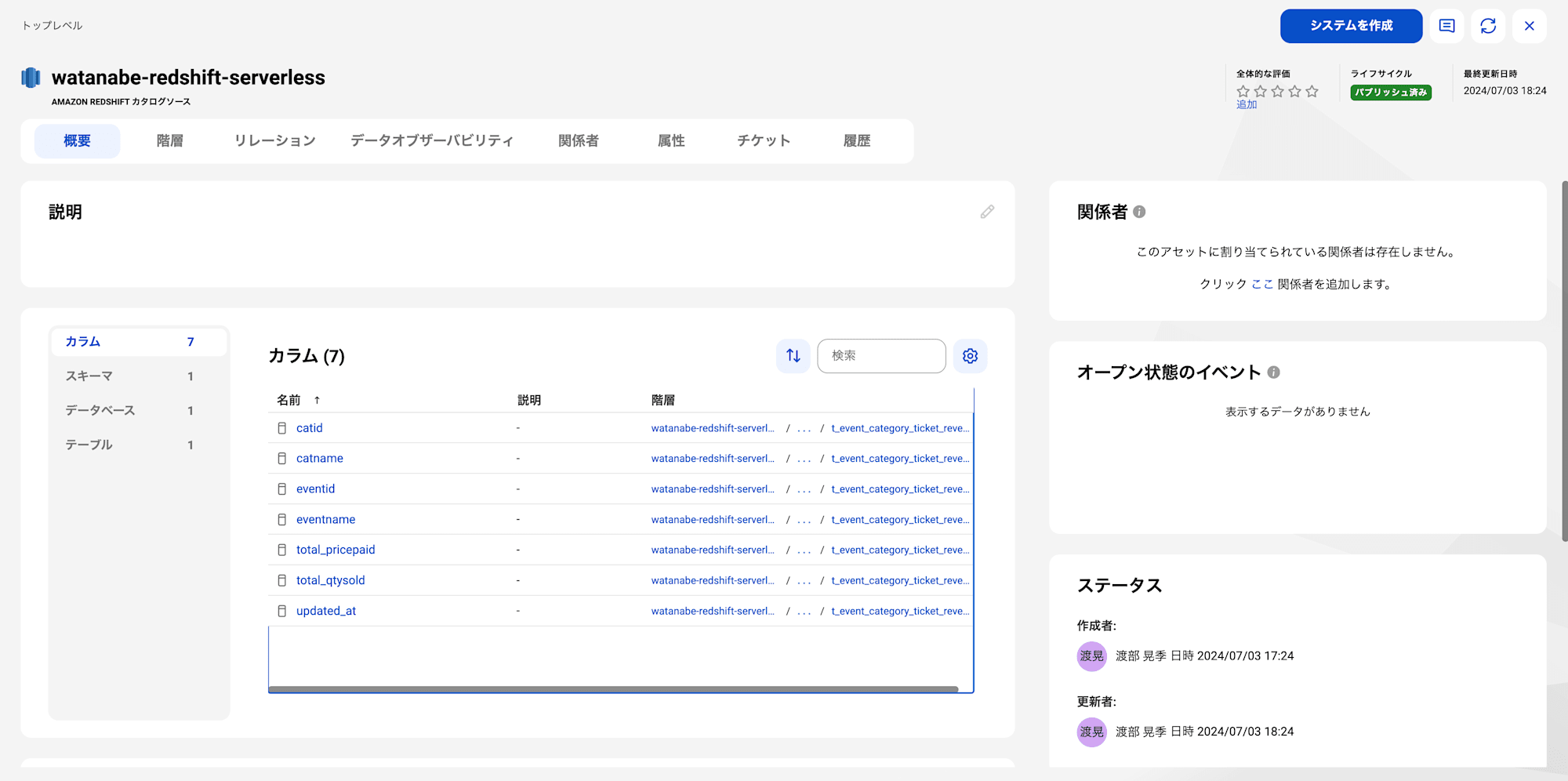
CDGCでカタログソースを開くと、データベースからカラムまでスキャンされています。
これにてスキャン成功です。
S3のスキャン
スキャン手順はRedshiftと同じなので迷うことはないと思います。
スキャンするS3バケット内のフォルダ階層は以下のとおりです。
tickitdb/
|-- allevents_pipe.txt
|-- allusers_pipe.txt
|-- category_pipe.txt
|-- date2008_pipe.txt
|-- listings_pipe.txt
|-- sales_tab.txt
|-- venue_pipe.txt
S3のコネクタは以下のように作成しました。
S3にはEC2のRoleからAssumeしてアクセスするように指定しています。

それではスキャンをしていきます。
MCCで新規 > Amazon S3を選択します。
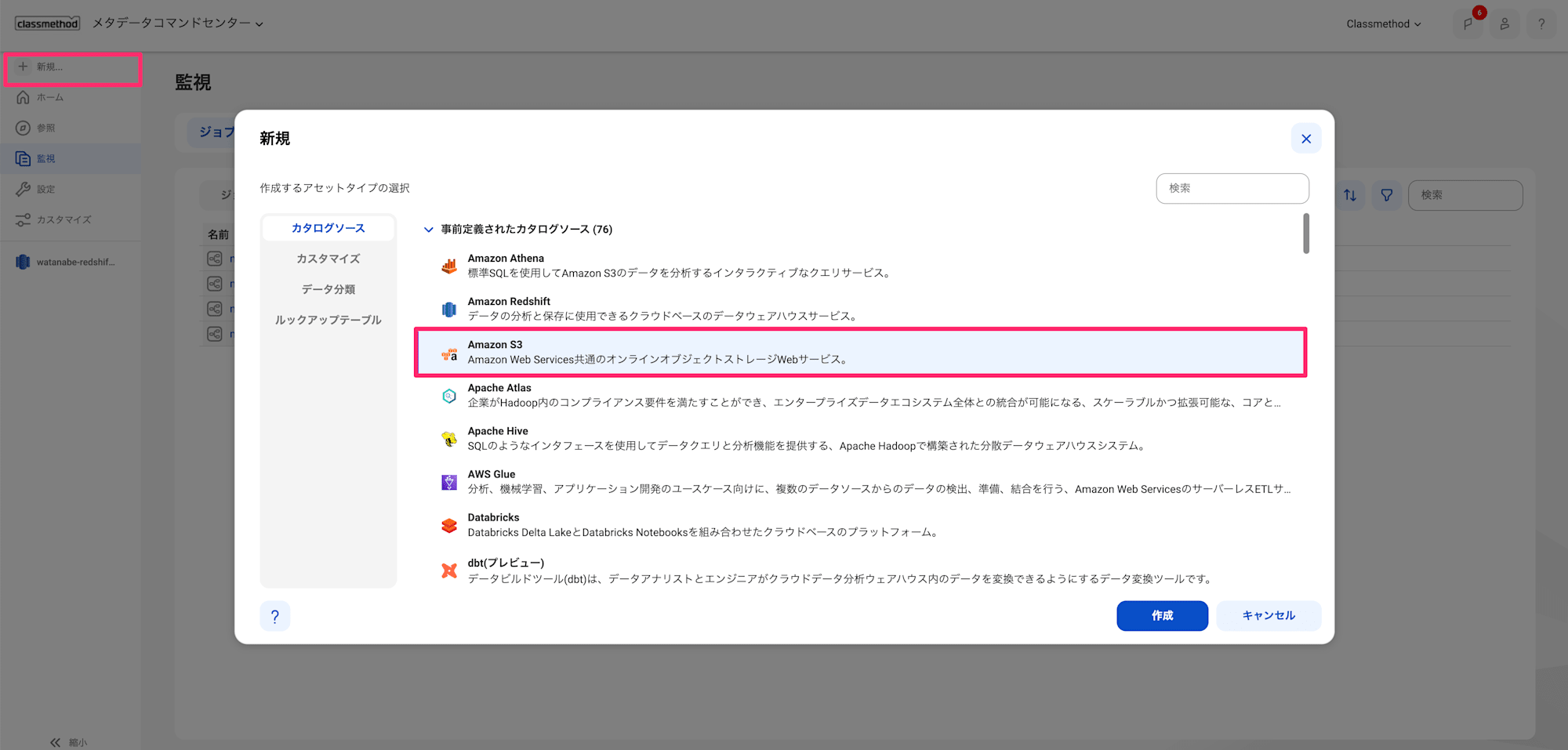
以下を設定します。テスト接続が成功すればOKです。
名前:任意のカタログソース名接続:Redshiftのコネクタ
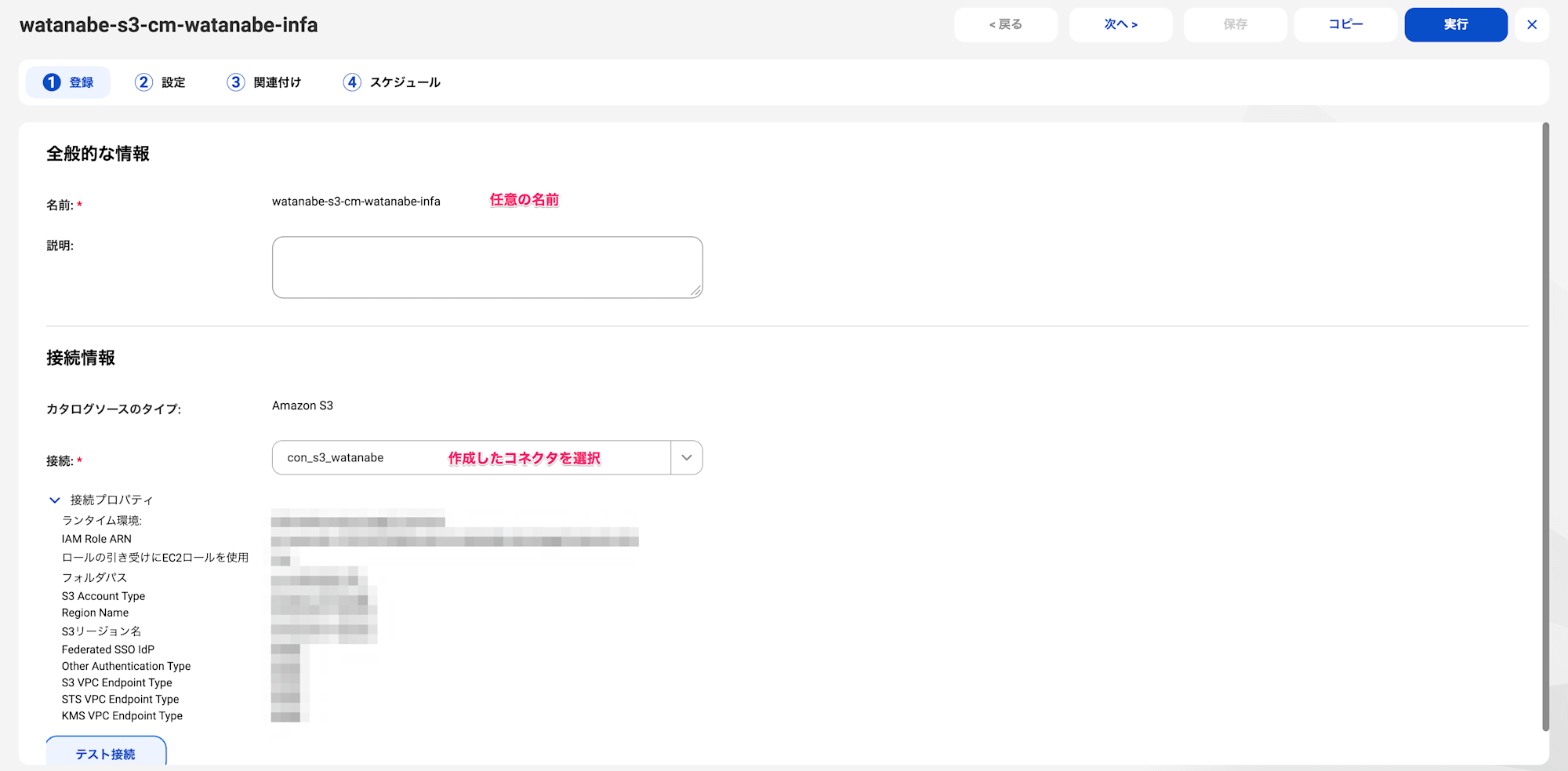
メタデータの抽出タブで以下のとおり設定します。
ランタイム環境:SecureAgentグループメタデータ変更オプション:保持(画像のとおりカタログソース変更時に、以前にインポートしたオブジェクトを残すか削除かを選択可能です)フィルタ:メタデータを含める、フォルダ、tickitdbを選択します。
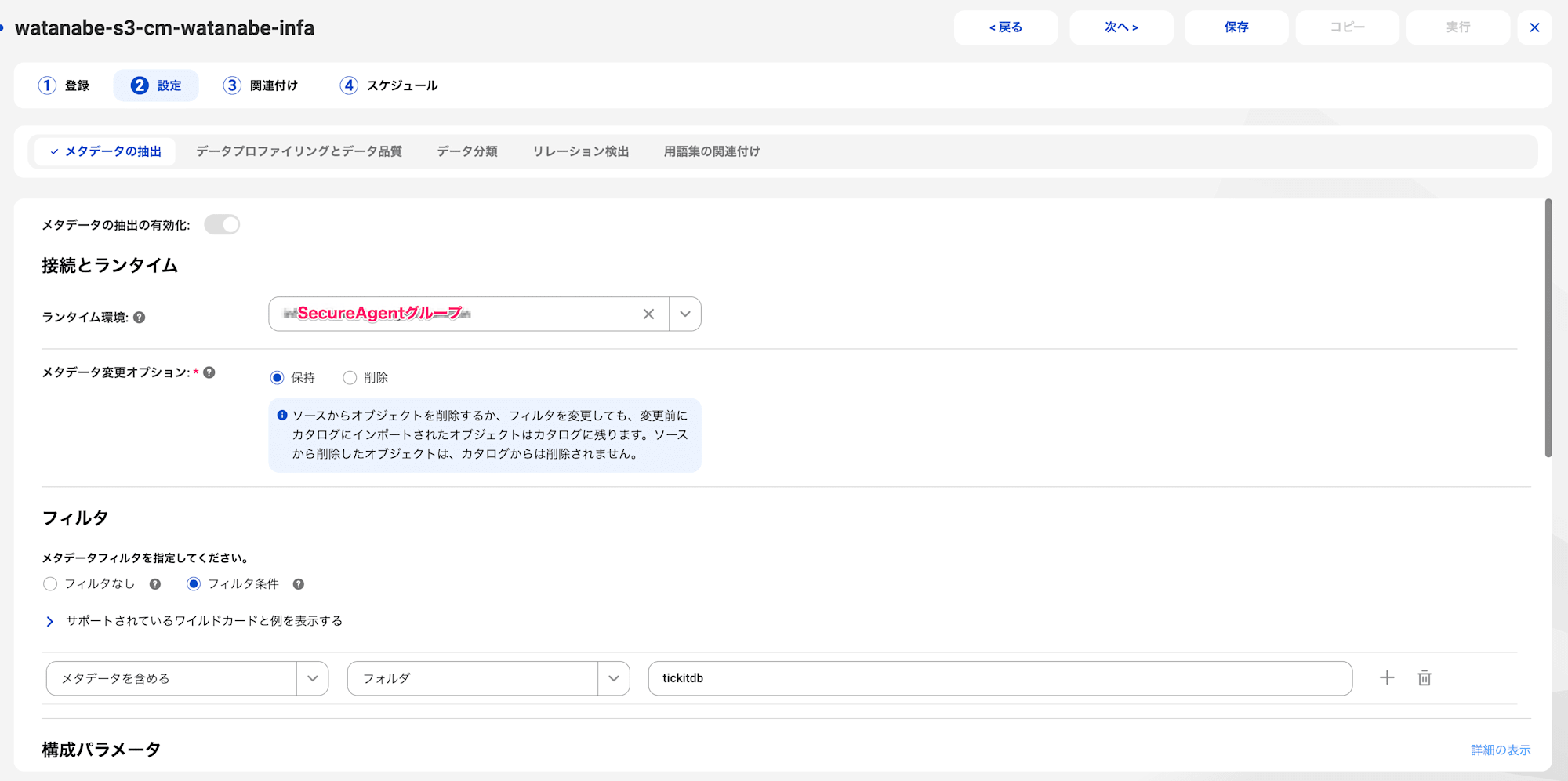
設定が完了したら、他はデフォルトのまま保存します。
スキャンを実行すると、今度はエラーにならず5分ほどでジョブが成功しました。
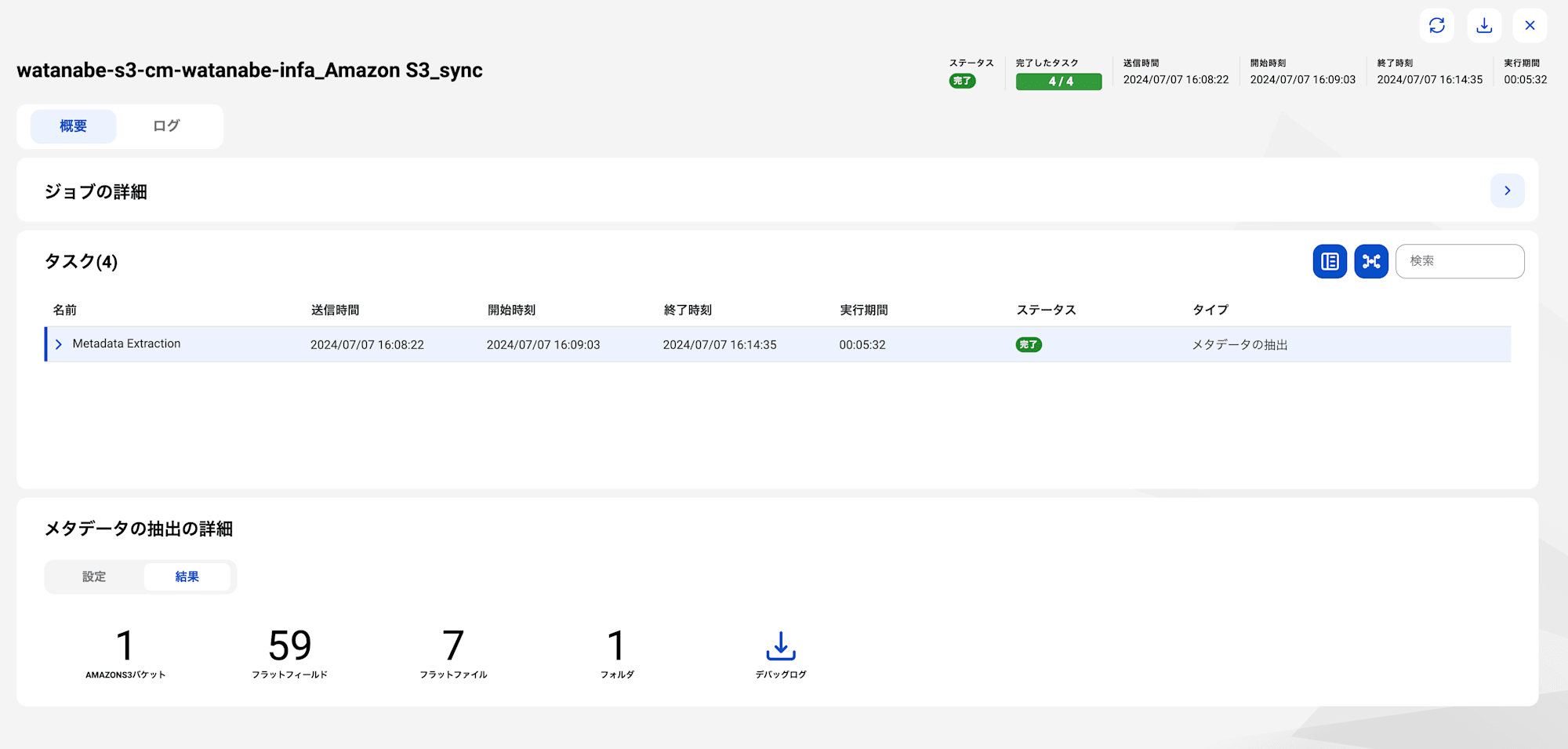
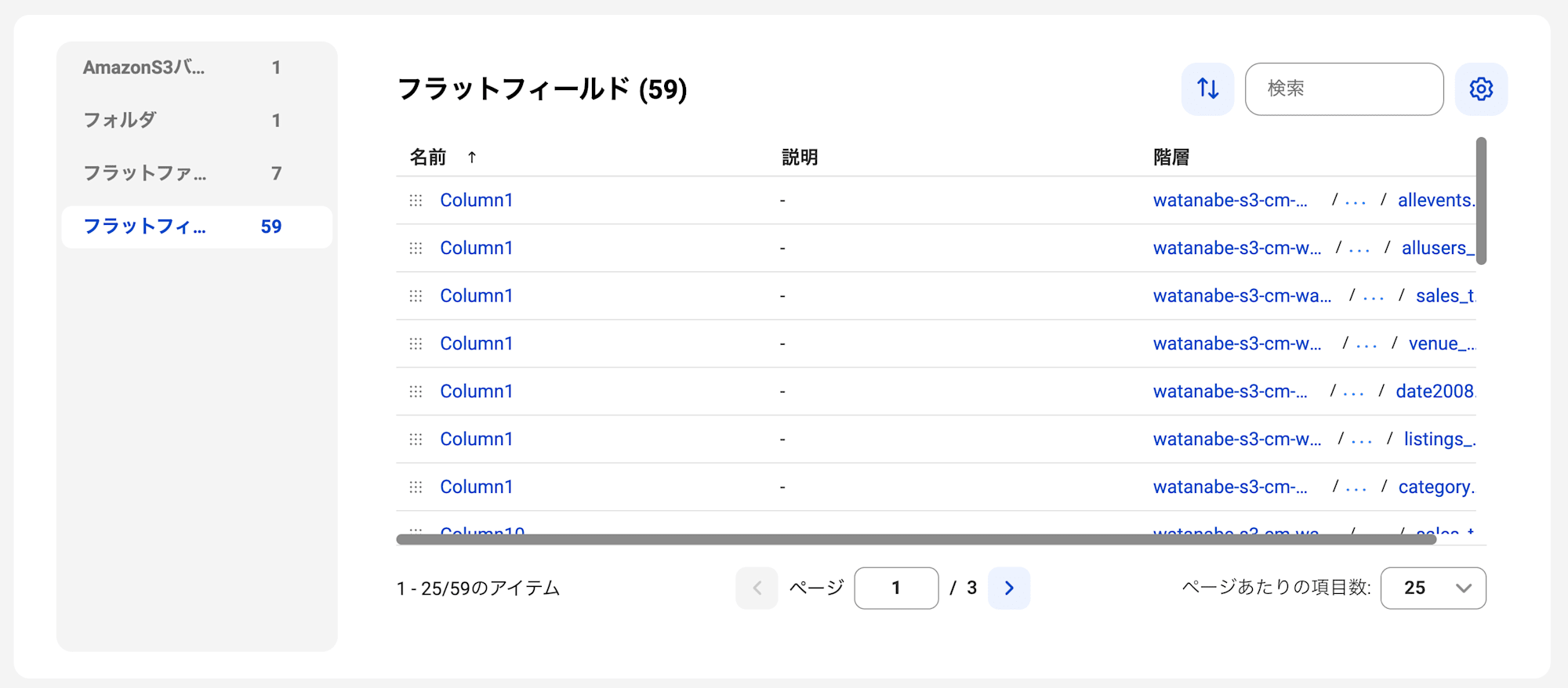
CDGCを確認するとS3に配置したファイルがすべて読み込まれていることが確認できました。
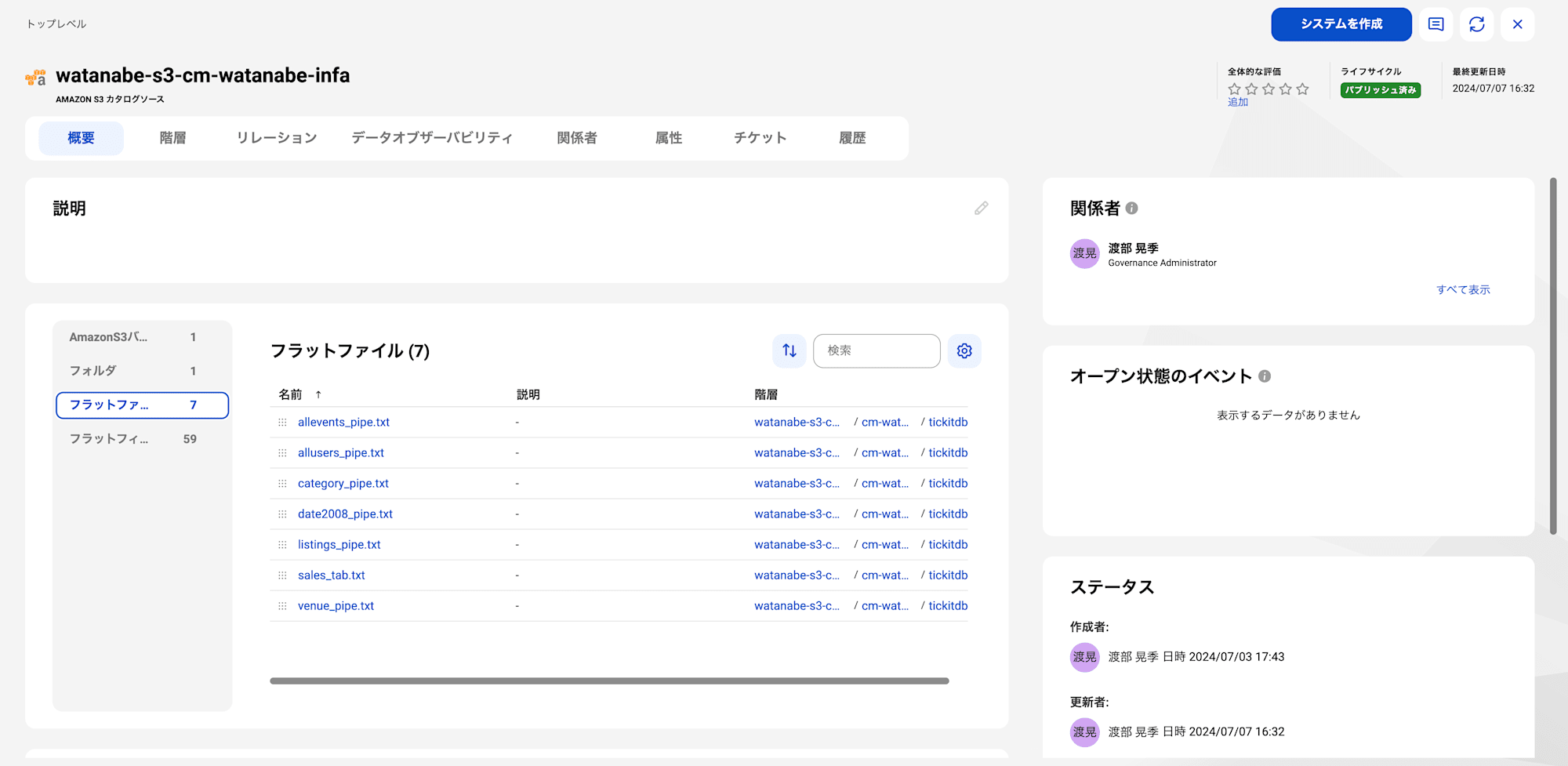
今回はサンプルファイルにヘッダがなかったため、項目がすべて「Column」で表示されています。
スキャン時に指定することもできるのですが、大変なのでデータ取込ルールとしてはヘッダは必要とするのが推奨ですね。
まとめ
事前準備抜かして、メタデータスキャンするまでにかかるクリック数を数えてみたのですが、 14回でスキャンができました。
本当にお手軽にメタデータ収集が可能です。
今回はデータ格納場所についての簡単なスキャンでスルーしたのですが、データ品質やデータ分類など、まだまだスキャン時に面白い機能がたくさんあります。
またETLのスキャンと組み合わせることでリネージュ取得も可能です。
今後本ブログでご紹介させていただければと思います。
以上、どなたかの参考になれば幸いです。







